A while ago an ISV client of mine was working on getting their app into the Embed program. Part of this process was to upload a bacpac with certain characteristics. The characteristics themselves are not relevant for this post but as I was helping them, but I thought I’d write this quick post to share how you can extract your bacpac files from a container, and how to use those bacpac files to create another one.
The setup
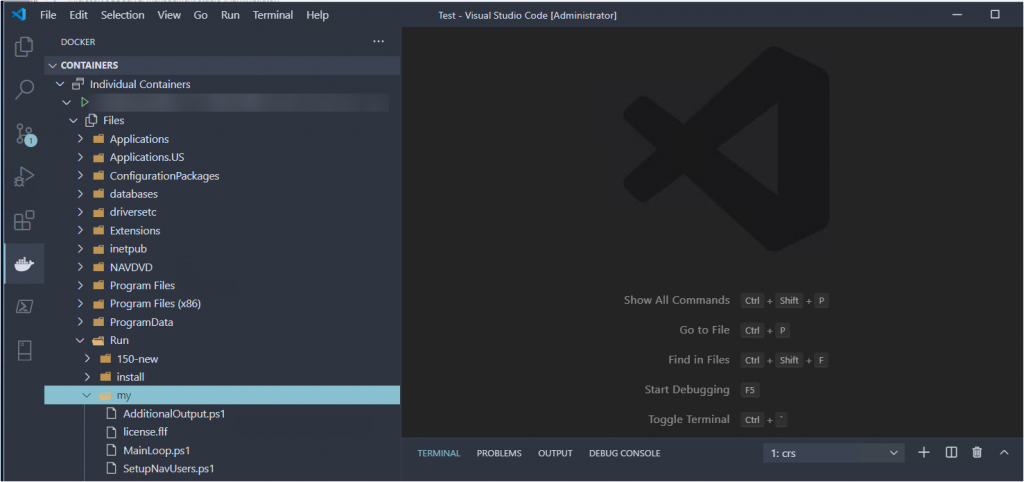
I’m starting out with a standard BC container, which was created using BcContainerHelper, and it is called DenSterDev. Coincidentally, I am also using BcContainerHelper to extract the bacpacs and to create the new container. I am using the “C:\ProgramData\BcContainerHelper folder to store the bacpacs, because that folder is recognized both inside and outside of the container.
Extract Bacpac Files
The container is multi-tenant, so there are two databases that we care about: one is the app database, and the other is the tenant database. Both of those are necessary to create the new container. If you have any apps installed on top of the standard container, those will be included in the bacpac file for the app database, and the bacpac for the tenant database contains the data itself.
The benefit of using BcContainerHelper is that we have very handy Cmdlets to get all this stuff in and out of containers, and the bacpacs is no exception. The command is very easy:
Export-BcContainerDatabasesAsBacpac ` -containerName 'DenSterDev' ` -tenant default ` -sqlCredential $Credential ` -bacpacFolder C:\ProgramData\BcContainerHelper ` -doNotCheckEntitlements
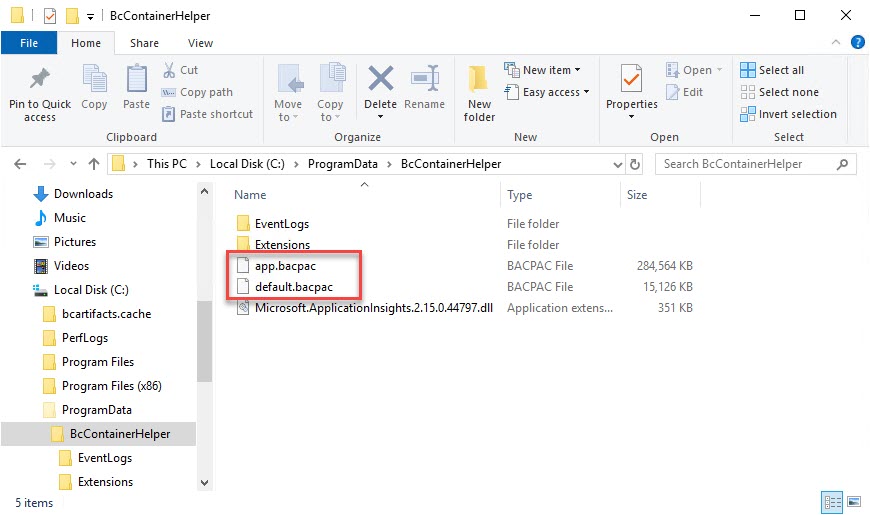
The tenant name is the default name of ‘default’ that is created in each standard BC container. The sqlCredential is a PSCredential object that was created during the container generation, using a username and a secure string password. As stated above, the bacpacFolder is a folder that can be accessed both in and out of the container. The entitlement flag is to bypass the check and prevent an error. When you execute this script, the bacpac files will show up in the bacpacFolder:
Create New Container from Bacpac
We are going to use these same bacpac files to create a new container. I’ll use the same container name:
New-BCContainer `
-accept_eula `
-containerName 'DenSterDev' `
-artifactUrl '<ProperArtifactURL>' `
-auth NavUserPassword `
-assignPremiumPlan `
-updateHosts `
-accept_outdated `
-Credential $Credential `
-additionalParameters @('--env appbacpac=C:\ProgramData\BcContainerHelper\app.bacpac','--env tenantbacpac=C:\ProgramData\BcContainerHelper\default.bacpac')
Same as before, the -Credential parameter contains a PSCredential object. Note that the -additionalParameters spans across multiple lines here, but that should go on the same line in your PowerShell editor.
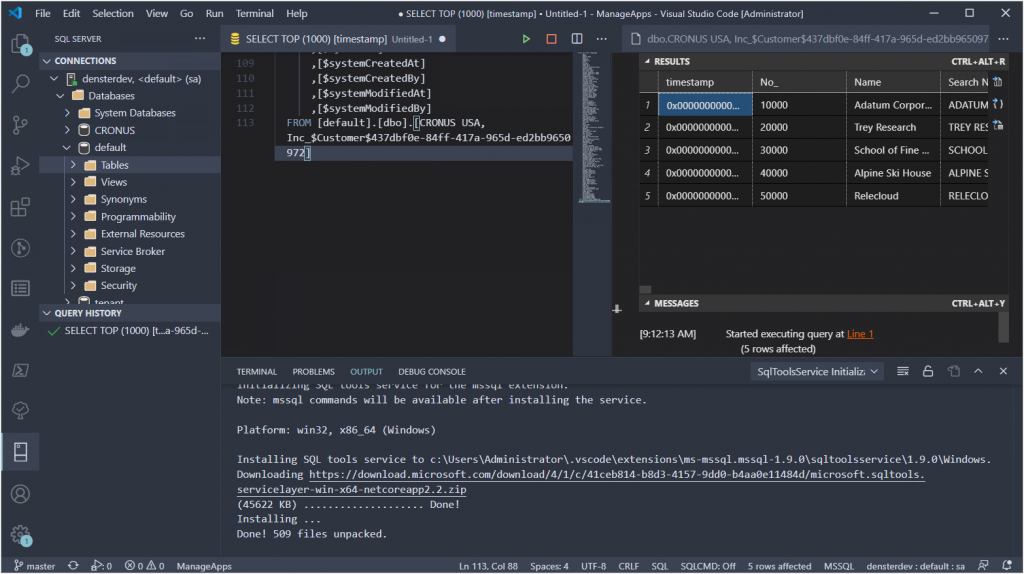
This command will download all the necessary artifacts and create the same container as the standard. The only difference will be that the app and tenant databases will be created from the bacpac files in your folder, instead of the standard database from the artifact. You can follow along with the script in the terminal window.
Nothing earth shattering, and made super easy by BcContainerHelper, but it took me a while to find the information and make this work. Hat’s off to Dmitry in the BC team, he was very patient with me as I got familiar with this process. Let me know in the comments if this was helpful or if you want to add anything.